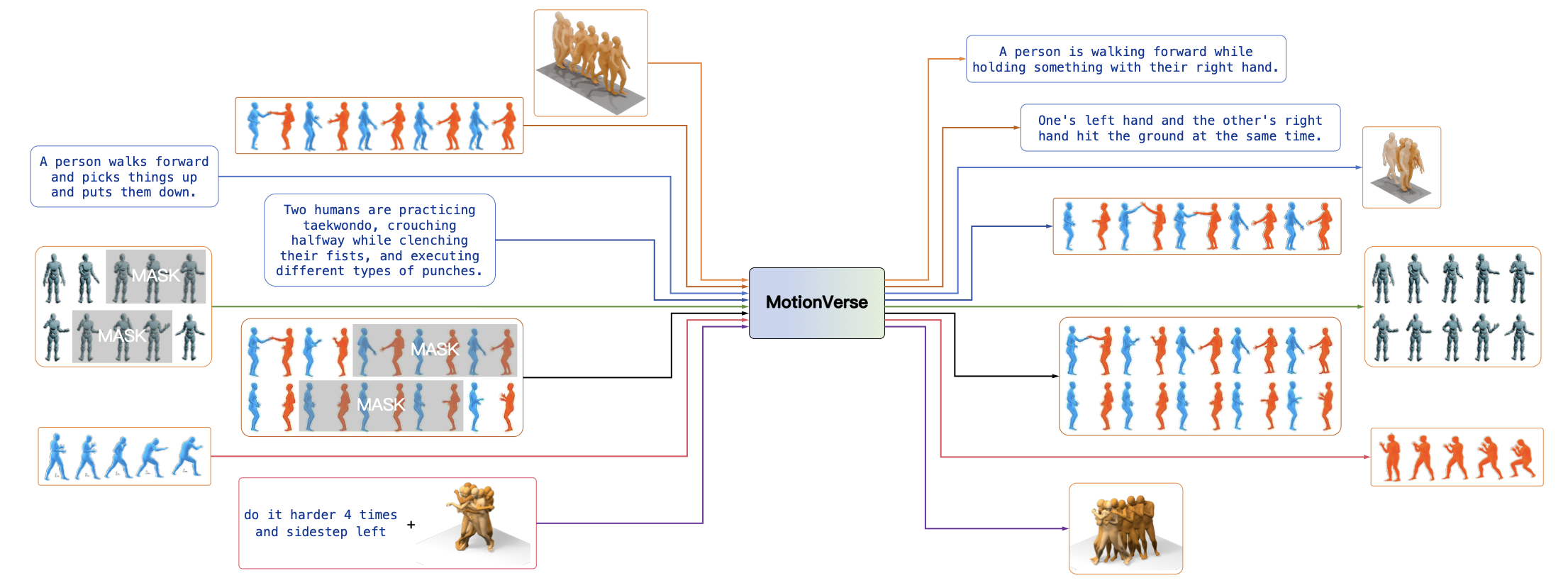
Existing motion-language frameworks primarily focus on isolated tasks such as single-person motion generation or understanding, while more complex scenarios, including human interaction, reaction, and motion editing, are typically addressed using task-specific architectures. Despite sharing common motion semantics and temporal structures, these heterogeneous behaviors are rarely unified within a single modeling paradigm, limiting transferable motion reasoning and general-purpose motion intelligence.
To address this limitation, we present MotionVerse, a unified motion-language framework for modeling both individual and interactive human behaviors. MotionVerse adopts a scalable multi-stream autoregressive formulation for residual motion tokens, enabling efficient long-sequence modeling while preserving fine-grained motion dynamics. To alleviate modality interference during joint optimization, we further introduce a modality-specialized Motion-Fusion mechanism with dedicated adaptation pathways for motion and language modeling.
Extensive experiments across diverse motion-language tasks demonstrate that MotionVerse achieves competitive performance in motion understanding, generation, interaction, reaction, and editing, validating its effectiveness as a scalable and general-purpose framework for unified motion modeling.
Single-person motion generation from textual descriptions. Benchmark: MotionX.
"The person uses the doorknob to open the door."
"A worker is inspecting a pyramid."
"A man makes a Battle Motion Straight Punch."
"The person is doing squats."
"A boxer is jabbing, crossing, and throwing scissor-like punches in a rhythmic pattern."
"A person appears to be swimming."
Two-person interactive motion generation from text. Benchmarks: InterHuman, InterX.
"Both stand facing each other; one approaches the other and greets with a handshake."
"One person attacks while the other avoids; taekwondo practice with offensive and defensive movements."
"They engage in a fencing bout, where they continuously lunge and parry."
Single-person motion captioning. Benchmark: MotionX.
Generated: "Someone is performing a Swivel Jump To Knee Tucks F."
Generated: "A warrior executes a Battle Motion Straight Punch."
Generated: "A woman is serving the tennis ball."
Generated: "A person sits down for casual conversation."
Generated: "A person walks slightly to their left casually."
Captioning of two-person interactive motion. Benchmarks: InterHuman, InterX.
Generated: "The other person lashes out with a right leg kick at the first person's waist, forcing the first person to take a step back."
Generated: "The second one attempts to kick the first one, but the first one evades the kick by stepping back with the left leg."
Generated: "The other person rushes forward attempting to pierce one's chest with a sword. One deflects the attack by swinging their own sword."
Generated: "One person extends the left leg to launch an attack; the other pulls back their right leg to avoid."
Generated: "The two are assuming attacking positions facing each other."
Single-person motion prediction and in-betweening. Benchmark: MotionX.
Timeline: ■ GT (given frames) ■ Model output
Two-person motion prediction and in-betweening. Benchmarks: InterHuman, InterX.
Timeline: ■ GT (given frames) ■ Model output
Given one person's motion, generate a plausible reaction from the other. Benchmarks: InterHuman, InterX.
■ Blue person = Input motion ■ Red person = Generated reaction
GT: one pulls the sword back and takes a step away, while the other makes a swinging motion with the left hand.
GT: one shoves the other while the other raises both hands to express powerlessness.
GT: the two step apart and stretch their arms out wide.
GT: two humans embrace each other.
GT: one person strikes the other, who then rotates and moves forward with three steps.
Edit existing motion via natural-language instructions. Benchmark: MotionFix.
Edit Instruction: "MAKE A WIDER TURN"
Source Motion
Edited Result
Edit Instruction: "Do the same faster the second time."
Source Motion
Edited Result
Edit Instruction: "Do a handstand and keep legs open."
Source Motion
Edited Result
Edit Instruction: "Start the squat earlier."
Source Motion
Edited Result
Edit Instruction: "Take smaller careless steps instead of hasty."
Source Motion
Edited Result
Edit Instruction: "Wave a bit slower and sway less."
Source Motion
Edited Result